What happens when a computer program runs? What happens when a developer compiles a program? These are questions fundamental to the process of Computer translation and are essential in understanding how computers ingest human-friendly languages and turn them into machine code.
Modern translation pipelines often make use of distributed systems like cloud-based solutions, dynamic link libraries, and virtualization. Advances in translation strategies are nothing short of inspiring. At their heart, however, these pipelines encompass several fundamental steps having been taking by Computer Scientists for decades.
Machine Translation Steps

Each step involved in translating high-level programming languages to machine code involves plenty of complexities. However, each can be regarded as completing one discrete stage of the process. Below, you’ll find a brief outline of each step and its role in the process of translating languages like C and Java into 1’s and 0’s.
Compiler
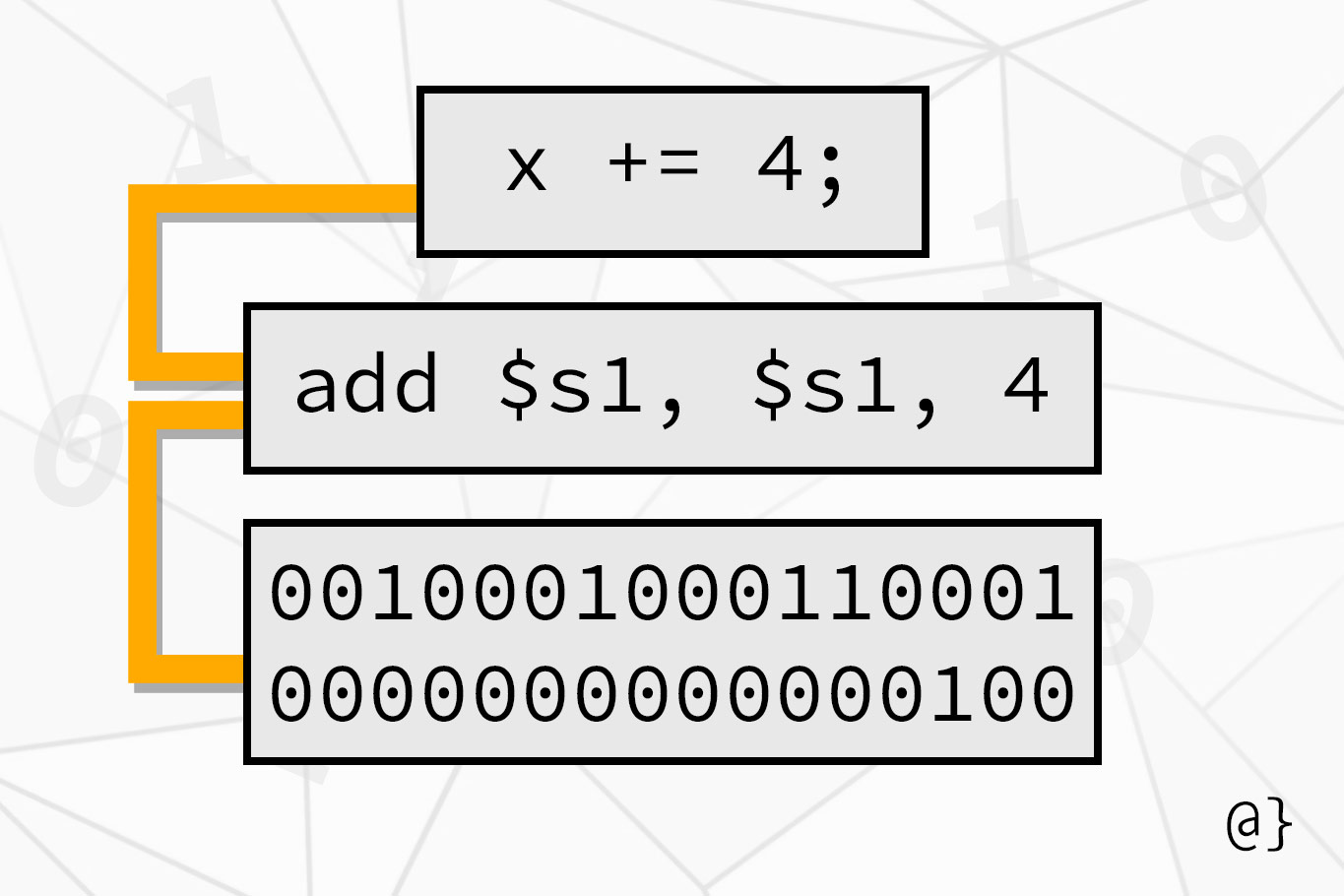
The compiler translates the programming language of one machine into the programming language of another. Generally, this process involves converting high-level language such as C into lower-level language like assembly code. The compiler is tasked with several jobs including preprocessing, lexical analysis, and code optimization.
Input: Takes a high-level language like C, Java, or C++
Output: Assembly language
Assembler
The assembly generates object code by translating the code generated by the compiler. Assemblers are tasked with creating a binary version of instructions generated by the compiler. This involves keeping track of labels used in portions of code that recur, such as procedures and static variables. The assembler does this with a Symbol table which consists of symbol:memory_address pairs.
Input: Assembly language
Output: Machine language objects
Linker
Sometimes referred to as the link editor, the Linker allows programs to only re-compile certain components rather than re-compiling the entire codebase. The linker gathers all the different assembly language programs generated by the assembler and “links” them together. There are three distinct steps involved in the linker’s role of computer translation:
- Puts unique code into memory as symbolic references
- Looks up addresses of data and instructions from the assembler files
- Links the references of procedures and labels from many files to single places in memory
In simple terms, the linker ensures that the program doesn’t use duplicated code, where unnecessary and turns many parts into a single entity. One main benefit of the linker is that it allows only parts of the program having been changed since the last compilation to necessitate re-compilation.
Input: Assembled files and modules
Output: Executable file with completely resolved references
Loader
The loader is responsible for loading the executable file into an operating system’s memory, completing the following sequence of actions:
- Allocates required memory for text and data segments
- Copies instructions and data from the linker’s executable file into memory
- Copies parameters to the
mainstack segment in memory - Initializes CPU registers and sets stack pointer to first free location
- Copies parameters into appropriate CPU registers, begins execution of
mainprogram, terminates on end.
Input: Executable File
Output: Depends on the program’s function
Discussion
Each step in the translation of human-readable code to executable machine code serves an essential purpose. The encapsulation of processes within each step allows programmers from different disciplines and backgrounds to focus on discrete optimizations in ways that all other programmers can develop.
To get an idea of how this discretization of translation works; check out the GNU Compiler Collection (GCC) which is an open-source project having spanned decades in open-source development. If you’re developing in C—you’re probably already familiar with it!
Frequently Asked Questions
What is Intermediate Code?
Intermediate code, sometimes called intermediate representation (IR), is data structures or code that has been generated during the process of compilation. It represents a more efficient model of source code to assist during the assembly process. Examples of intermediate code include Java Byte Code, Microsoft’s Common Intermediate Language, and the C Intermediate Language.